AWS服务和Kafka集群实操日记
简介
最近有一个项目需要使用AWS服务,鉴于我是第一次上手AWS和使用其中的服务,我认为有必要写一篇博客记录下我新接触到的技术,一些理解和感悟,并且保留一些实际操作经历方便我回顾和重新使用其中的一些命令。
这个项目涉及到了
- Amazon MSK也就是Fully Managed Apache Kafka,说白了就是一个kafka集群
- Amazon的Iot Core,是一个MQTT broker类似的东西
- Amazon的Lambda,一个支持多编程语言的serverless平台
- Amazon的S3,Scalable Storage in the Cloud
- Amazon的IAM的权限控制
- Amazon的CloudWatch - 类似于Grafana的平台
这篇日记将会围绕上述内容展开,并且将所有服务串成一个数据流
正文
业务流程
我们从数据的入口开始逐步追随数据的脚步完成追踪从而串联所有使用到的服务。
Iot Core将会作为入口,接受来自iot设备或者其他使用mqtt协议的服务,将接收到的数据使用Message routing的Rules功能将信息转发到kafka的topic中或者发送到Lambda经过处理写入S3的Json文件中。
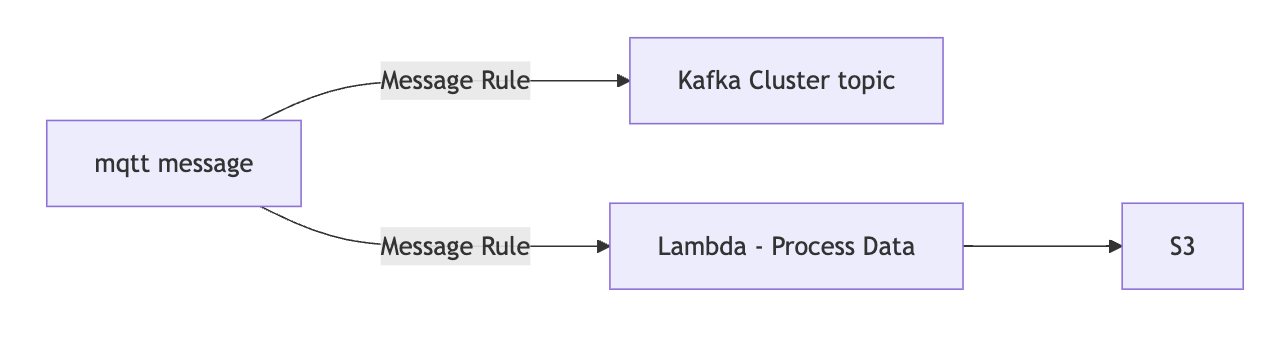
1 | graph LR |
IAM权限控制
其中如果Iot Core在遇到错误抛出将会将日志写入CloudWatch服务。完成上述要求首先要求用户配置多个服务的Policy,然后将不同的Policy分配给多种Role,然后这些服务将会使用Role提供的权限来操作AWS中的各类服务,总而言之Policy是包含多单个权限的集合,例如s3:ListBucket就是Policy中所有权限的例子。
而Role则包含一个或多个Policy的集合,例如分别有S3 Admin Policy和CloudWatch Write Policy,这些将会为Role中的Policy。只有将拥有相应权限的Role分配给AWS服务的instance,这个instance才能操作和有访问权限,这是一大先决条件。
MSK配置
首先MSK分为Provisioned和Serverless两种类型,其中serverless不能具有除了IAM之外的验证方式,这就使得如果想让Iot core和msk搭配使用,必须要使用provision版本的,因为Iot core rule只支持使用SASL/SCRAM身份验证或者SSL身份验证。
此外如果想从外部访问MSK集群中的节点去创建topic有多种方式,而我采用的是使用一个EC2的client machine,也就是一台虚拟机作为一个跳板机,并且在跳板机器上搭建代理,使得从外部可以通过代理连接到Amazon内部与EC2同一VPC网络下的节点,但是很重要的一点是不能疏忽了MSK和EC2的防火墙配置是否放通,如果不放通会无法连接,我在这里排查了很久才发现是防火墙的问题
关于如何设置跳板机可以参见官方的文档https://docs.aws.amazon.com/msk/latest/developerguide/create-client-machine.html
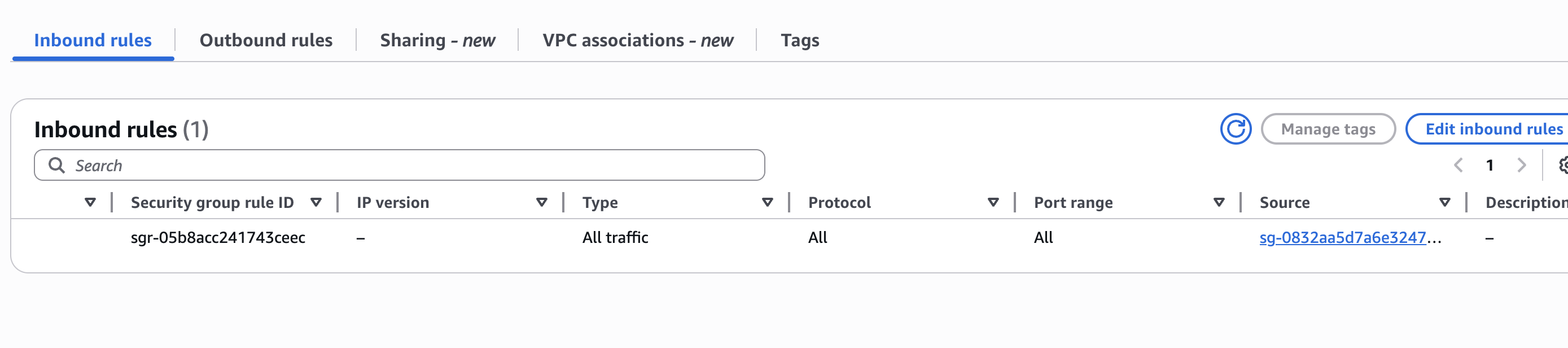
讲清楚了访问,我们再深入讲讲连接和权限控制,首先确保EC2的IAM Role有权限访问MSK集群的节点和topic,然后连接跳板机可以通过如下命令完成topic的创建和订阅和发送消息到topic
1 | subscribe topic |
其中如果遇到了诸如提示Error while executing topic command : The AdminClient thread has exited. Call: createTopics,基本上可以判定是权限问题,请先检查你配置的IAM和SASL/SCRAM/SSL是否正确,其中IAM如果在EC2上只要在网站上正确配置了IAM role,那么使用那个IP就可以直接使用IAM方式访问。
1 | [ec2-user@ bin]$ ./kafka-topics.sh --create --bootstrap-server url:port --topic your_topic --partitions 6 --replication-factor 2 |
Iot Core设置
我们可以通过打开AWS IoT - Message routing - Rules,来新增一条规则,我这里记录我使用Rule将数据转发到Kafka的过程,首先我们选择Rule actions为Kafka,并且在Destination里添加一个VPC,这个同样需要对应的IAM Role去完成,接着我们可以设置Kafka topic为你之前创建的topic,Key我填写了${clientid()},主要是提供给kafka做数据分区使用,如果单个key太多可能会导致某个分区中的内容过多导致倾斜。
特别需要注意的是在SASL Configuration中,username和password需要先在AWS Secrets Manager中填写用户密码的键值对,然后绑定在Key Management Service (KMS)中生成的Key即可,后续的访问中如果使用SASL/SCRAM,这里设置的键值对就是你的用户密码
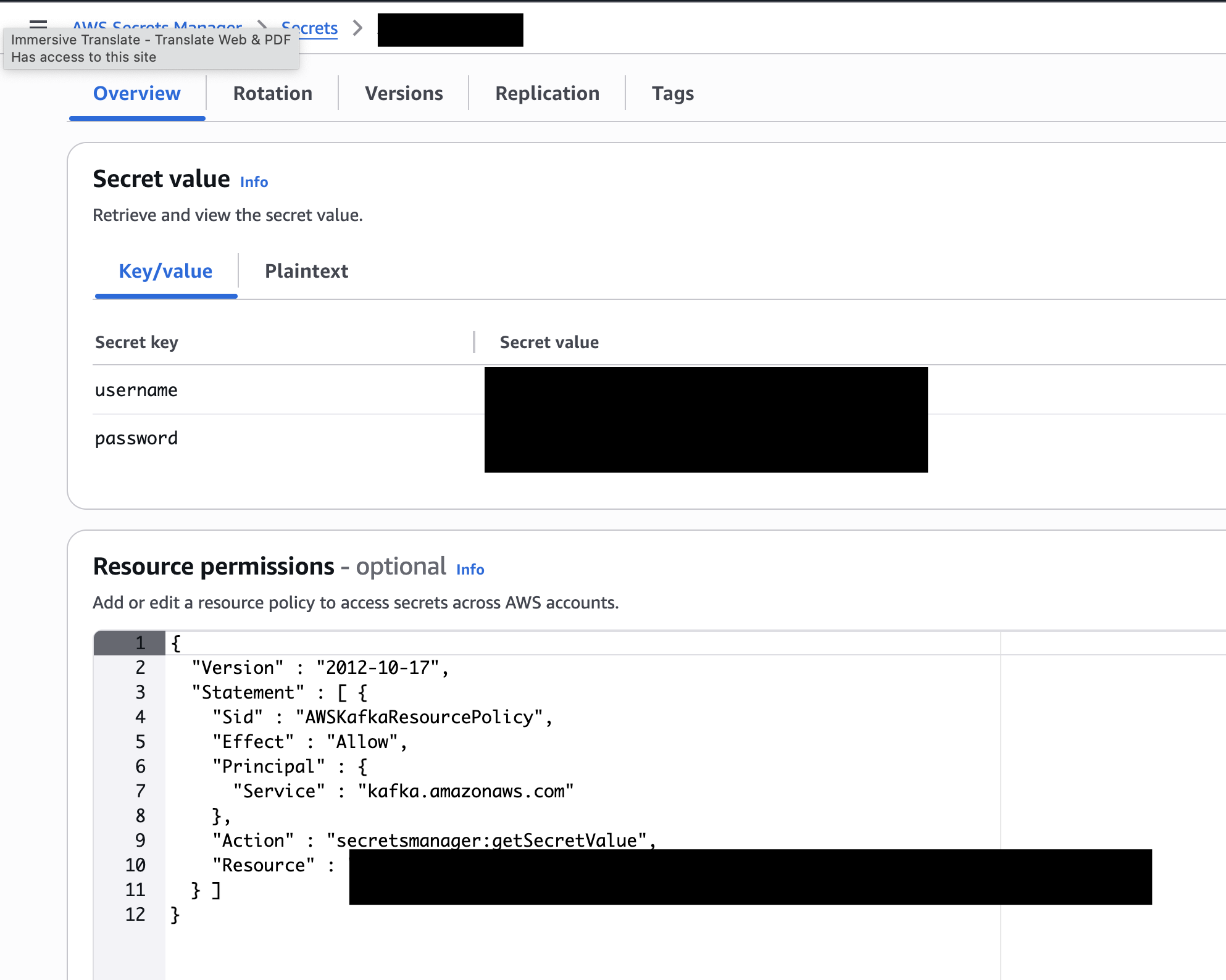
然后我们需要使用这个来获取存储在Secrets Manager中的键值,这个是用户名,密码则替换username即可 ${get_secret('AmazonMSK_iot', 'SecretString', 'username', 'you role arn')}
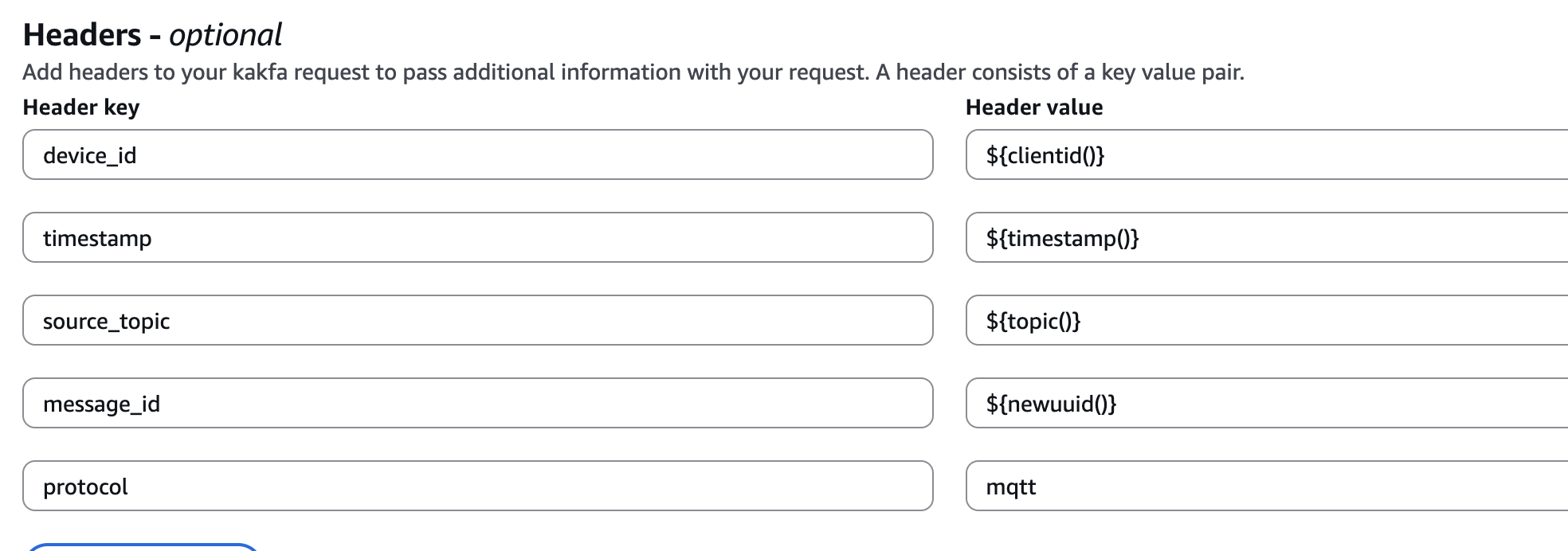
当然你也可以设置一些header来方便识别信息,但是如果设置过多也许会些许影响性能
Lambda设置
只需要在Lambda中添加一个Functions,然后在Iot core中的rule设置一个action到这个function就可以将iot的数据一同发送过来,然后我就在这里合并获取到的mqtt数据然后上传到s3,如果直接将数据通过iot core的rule转发到s3的话,会为每条数据生成一个文件,似乎不方便管理和查看,所以为什么这里要使用Lambda去转发。
但是由于我这里直接而使用了Lambda去上传数据到s3,并没有做任何缓存,如果数据量比较大可能会出问题
结尾
这就是所有我最近上手的AWS服务了,如果有什么新的,以后可以再加
AWS服务和Kafka集群实操日记